이번 강의에서는 CNN의 훌륭한 아키텍쳐들을 몇가지 살펴볼 것이다.
Contents
1. AlexNet
2. VGGNet
3. GoogLeNet
4. ResNet
Review
- 1998년 처음으로 CNN이라는 개념을 개발한 네트워크로 LeNet이 있었다.
- Conv layer와 subsampling(average pooling layer) layer를 거쳐 마지막에 1차원벡터로 쫙펴주는 FC layer가 있는 구조였다.

AlexNet
가장먼저 2012년에 ImageNet 이미지를 기반으로 한 화상 인식 대회인 ILSVRC-2012의 우승자 AlexNet부터 보자.


- 기본 구조는 [Conv-Max pooling-(normalization)] x 2 - CONV-CONV-CONV - Max pooling - [FC-FC-FC]
- 5개의 CONV layer와 3개의 FC layer 그리고 사이의 pooling layer로 LeNet과 크게 다르지 않다.
- 다만 GPU를 두개로 나눠서 학습했다는게 일단은 큰 차이점이 되겠다.
* Normalization 은 AlexNet 이후로 필요하지 않아서 사용X
1. Layer의 파라미터 변화
1) Convolutional layer

input data = (227 * 227 * 3) #그림에는 224인데 227의 오타
filter = (11 * 11 * 3) & filter 96개
Stride = 4
# Output size = (N - F)/stride + 1 => (227 - 11)/4 + 1 = 55
- Output size = (55 * 55 * 96)
#그런데 당시 메모리 용량이 3G밖에 안돼서 filter를 48개씩 데이터를 반으로 나눠서 넣었기 때문에 (55*55*48) x 2개
- 파라미터의 개수 : (업데이트해나갈 값, 가중치같은것) (11*11*3) * 96 #모든필터안의 총 가중치 개수
2) Maxpooling layer

input data = 1st layer의 Conv layer ouput = (55*55*96)
filter = 3*3*96 (#그림에는 Pooling layer는 생략돼있다)
stride = 2
# Output size = (N - F)/stride + 1 => (55 - 3)/2 + 1 = 27
- Output size = (27 * 27 * 96)
- 파라미터 개수 : 0 !
⇒ Pooling layer는 위치한 필터 안의 데이터 값 중 특정값을 골라서 데이터사이즈만 변환시키기 때문에, 따로 가중치가 없다.
2. 전체 layer 구조 확인 & AlexNet의 특징

1) 전체 layer 구조
(CONV1-MAX Pooling1) - (CONV2-MAX Pooling2) - CONV3 - CONV4 - CONV5 - MAX Pooling3 - FC 6,7,8
마지막 Fully Connected layer는 Softmax함수를 거쳐 1000개의 ImageNet classes로 최종분류된다.
2) AlexNet 특징
특징
1. 비선형함수로 ReLU를 사용
2. regularization
① Data augmentation(regularization의 일환으로 train data에 변형을 주는 것)을 많이 했다.
: flipping, jittering, clipping, color normalization 모두 적용
② Dropout 0.5
3. batch size 128
Batch Normalization
- 딥러닝에서는 수많은 hiden layer를 거치면서, 초기데이터의 분포가 변하게 된다.
- 학습데이터와 테스트데이터셋의 분포가 다르면 예측이 적절히 이루어지지 않듯이, 뉴럴네트워크에서도 layer마다 들어오는 데이터의 분포가 달라지게 되면 적절한 학습이 이루어지지 않는다.
- 이를 해결하기 위해 매층마다 데이터의 분포를 재조절해주는 Batch Normalization이 등장한다.
Batch란 전체 데이터를 세트를 나눠서 학습시킬때, 은닉층에 들어온 데이터세트를 말한다.
1. 정규화 : 배치데이터의 평균, 분산을 이용해 정규화
2. scale(범위조정), shift(이동) : scale을 위해 γ, shift에는 값을 하이퍼파라미터로 사용하고, backpropagation을 통해 이 값들 또한 학습한다.
4. SGD Momentum 방식 Optimization
5. Learning rate 1e-2 에서 시작해 val accuracy가 더이상 올라가지 않는 학습지점부터 서서히 1e-10으로 내림
6. weight decay : L2
Weight decay
학습과정에서 과적합이 발생하며 모델의 복잡도가 너무 높아지면 학습데이터에 대한 loss값은 최소가 될 수 있지만, 실제 test data에서는 accuracy가 떨어진다. 특정 feature에 너무 큰 가중치가 업데이트 되지 않도록 loss function에 weight가 커질 경우에 대한 패널티를 부여하고, 주로 L1 또는 L2 regularization을 사용한다.
7. ensemble 기법 사용
3) 전체 Layer 특징 요약


전체 Layer 특징
앞서 말했듯이, 당시 GPU 메모리가 3GB밖에 안 돼서 학습과정에서 2개의 GPU에 데이터를 반반씩 나눠서 학습을 진행했다.
(1) CONV1, 2, 4, 5
- 그림을 보면 CONV1,2,4,5 layer에서는 2그룹으로 나눠진 필터에 해당하는 feature map만 학습하게 된다.
- 서로 다른 GPU에 데이터가 올려져 있어서 같은 GPU안에 있는 feature만 보고 학습하게 된다.
(2) CONV3, FC6, 7, 8
- 그런데 이 layer들은 특이하게(?) GPU간의 통신을 허용해서 이전 layer의 모든 feature map을 볼 수 있다.
- 그래서 이전 layer에서 들어오는 모든 input의 feature map을 참고할 수 있게 된다.
3. CNN 기반 모델의 발전과정

AlexNet은 2012년에 ImageNet 대회에서 처음으로 CNN을 기반으로 한 모델의 우승을 거머쥐었고, 이를 시작으로 CNN이 발전하면서 앞서 배운 transfer learning 의 기반 모델로도 많이 사용되었다.
2013년도의 우승자였던 ZFNet은 AlexNet의 파라미터값만 바꿔서 출전했는데도 우승을 했다.
그리고 2014년도의 GoogleNet과 VGG이 나왔는데, 확실히 layer가 깊어지면서 성능도 우수해졌다.
VGGNet

VGGNet의 AlexNet과 가장 큰 차이점은 ① layer가 깊어졌다 (8에서 16~19layers로) ② 3x3 , stride 1, pad1 CONV필터와 2x2 stride 2 MAX POOL 필터만 사용했다.
layer가 깊어지는만큼 non-linearity가 증가하니 더 자세히 특징을 잡아낼 수가 있다.
그런데 AlexNet은 11x11, 5x5, 3x3 의 필터를 사용했고, stride와 pad도 달랐는데, 작은 필터만 여러번 사용한 특별한 이유가 있을까?
1. 수용영역 (receptive filter)

합성곱 계산방식은 계속 봐도 아직 헷갈린다. 그냥 행렬곱이랑 같은건지 뭔지.
확실히 하자면, 하나의 필터위치에서 성분곱(element-wise product, 같은"위치"원소의 곱)의 "합"을 구한 것이다.
위의 그림에서는 필터가 output으로 2x2의 특성맵(feature map)을 출력하고 있다. 이 특성맵은 필터가 바라본 4번의 영역들 중 해당 필터와 가장 비슷한 정도를 점수로 나타냈다고 이해했다.

layer를 거치면서 저수준특성에서 고수준특성으로 조합한다는 말이 무슨말인가 하면,
위의 그림처럼 첫번째 레이어에서 필터가 바라본 하나의 위치는 다음 피처맵의 1칸으로 들어가게 되고,
그 다음 레이어에서 다시 새로운 필터로 바라볼땐, 그 한칸들을 여러칸 한번에 바라본 뒤, 다음레이어의 한칸으로 보내기 때문에, 결과적으로는 두번째 레이어가 첫번째 레이어보다 최초의 피처맵의 더 넓은 부분을 바라보게 된 것과 같다.

다시 VGGNet이야기로 돌아가서, 3x3 필터를 2번 사용한 것과, 처음부터 7x7 필터를 사용한 것을 비교해보자.
왼쪽 그림에서, 3x3을 2번 거치면, 3번째 피처맵의 한칸(파란색)은 첫번째 피처맵의 5x5를 바라본 것과 같다. 이 단계를 한번 더 거치면 4번째 피처맵의 한칸은 첫번째 피처맵의 7x7 부분을 바라본것과 같게 된다.
여기서 depth는 표현하지 않았는데, 피처맵의 depth 를 C(채널)라고 했을 때 3x3을 3번할 때의 파라미터 개수는 (3x3xC)x3 xC = 27 C^2
7x7를 1번할 때의 파라미터 개수는 (7x7xC) xC = 49C^2 으로 파라미터 수는 확 줄어드는 효과가 있다.

여기서 C를 두번 곱한게 헷갈렸는데, 왼쪽 그림 다시보면, 필터 자체의 depth도 input의 depth와 같아야 하고, input과 output의 depth를 유지해주려면, 이 필터가 depth개만큼 있어야 다음층의 depth도 유지되기 때문에 C를 한번 더 곱하는 것이다.
2. VGGNet의 총 파라미터 개수

그래서 이 16개의 층에 들어있는 파라미터 개수를 구하면 이렇게 나온다~
- 일반적으로 필터개수는 32, 64, 128, 256, 512 (2의제곱승)을 사용하고, 위에서도 그렇게 적용한 걸 볼 수 있다.
- 그리고 원래는 bias도 더해줘야 하는데, 일단 생략하고 계산한 예시를 들었다.
여기서 중요하게 볼 것은최종 파라미터의 개수와 용량이다.
(1) 파라미터 개수가 많다!
- 총 개수는 138M (1억 3800만), FC layer에도 1억개가 넘는 파라미터가 있다. AlexNet이 6M개이다.
- 후에 이걸 개선하고자 하는 이슈가 등장한다.
(2) 메모리 용량이 크다. forward pass만 계산해도 용량이 커서 무겁다는 단점이 있다. 사진 하나 분석하는데 96MB!!!
⇒ 그리고 메모리용량은 대부분 앞쪽CONV layer에, 파라미터개수는 뒤쪽 FC layer에 집중돼있다.
그래서 최근에는 아예 특정 층을 버리는 방법을 사용하기도 한다.
⇒ 장점 중 하나는 FC layer가 generalize가 잘 되어 있어서 다른 사진을 갖다넣어도 분류가 잘 된다고 한다. 이런 모델을 사용해서 training transferring을 할 수 있지 않을까 싶다 (개념적으로 ㅎㅎ)
GoogLeNet

1. 특징
- 더 깊어진 layer
- Inception module이란 것을 사용함
- FC layer가 사라짐 ⇒ 파라미터 개수가 집중돼있는 layer를 없애 파라미터 개수를 효과적으로 줄였다.
- 파라미터가 5M개밖에 없다! AlexNet이 6M개인데!
1-1) Inception module
네트워크와 네트워크 사이에 있는 네트워크라는 개념의 local topology를 만들었고, 이들간의 네트워크를 Inception module이라 한다. 영화 인셉션에서 꿈속의 꿈속의 꿈이 있는 것처럼, 네트워크 안에 네트워크가 있는 것이다.
원래 하나의 layer에는 하나의 필터를 적용했었는데, GoogleNet은 여러종류의 필터를 병렬적으로 같은 input layer에 적용해 나온 값들을 depth방향으로 concatenate (쌓았다), 즉 층층이 쌓아올려서 1개의 Tensor output을 만들게된다. 기존의 같은종류의 필터가 여러장이면 output을 depth방향으로 쌓아올렸들이 말이다

ㅣ과정
- 그림은 3가지 conv 필터와 1가지 pooling 필터를 이용해 Inception module을 구성한 모습이다.
- 생략돼있지만, input의 spatial dimension (WxH)이 유지되도록 stride와 padding이 알아서 잘 설정돼있다고 한다.
- 따라서 각 필터의 output 의 spatial dimension은 28x28로 동일하고 depth만 필터의 개수에 따라서 달라진다.
- pooling layer는 depth size는 그대로 유지한다.
- 여기서 input은 이전 inception module의 output임 (전체input 노노)
ㅣ결과
- 총 28x28x672 개의 output data가 생성되고, 이를 위해 854M(8억 5400만)개의 합성곱연산이 필요하다.
→ Inception module 안에서의 계산량이 많다.
- Pooling layer는 feature depth를 유지하기 때문에 concatenation은 항상 증가!할 수밖에 없다.
⇒ 해결책
- 계산량을 줄이고 depth를 줄이기 위해 1x1 필터층인 일명 bottle neck layer를 추가한다!

- 다시 remind해보자면
- 1x1필터를 32개 깔면 output은 spatial dimension은 유지하면서 depth는 32개로 줄어들 수 있기 때문!

- inception module 안에 bottle neck layer를 추가해보면 합성곱계산량이 358M개로 줄어드는 것을 볼 수 있다.
- pooling layer의 경우 depth를 줄이기 위해 이후에 1x1 conv layer를 깔게 되는데, 이를 통해 depth도 줄여 4개의 output을 모두 concatenate한 depth 또한 줄일 수 있다.
2. 전체네트워크 구조

① Stem Network
- 일반적인 네트워크 구조로 시작한다.
- Conv-Pool-Conv-Conv-Pool
② Inception Modules 이 쌓이는 중간층
③ Classifier output
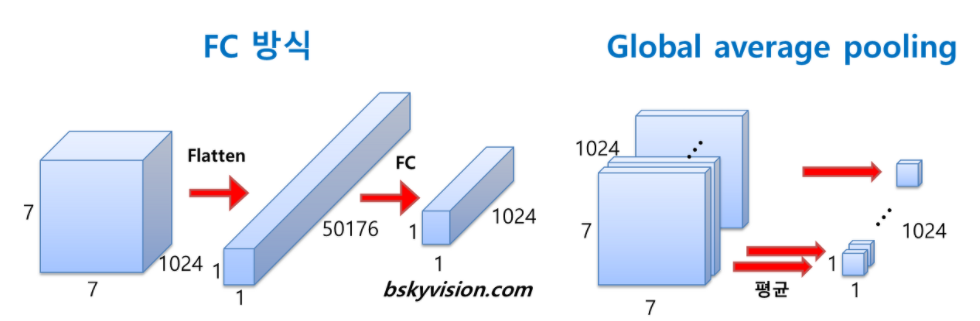
- 특히 FC layer를 없애서 parameter를 확 줄였는데, 그래도 잘 돌아갔다고 한다.
- FC layer 대신 global average pooling layer(첫번째보라색)을 깔았는데, 기존 FC layer는 feature map을 1차원벡터로 펼쳐서 Relu와 같은 활성화함수를 거친뒤 Softmax로 분류하게 되었는데, Global Average Pooling은 직전층에서 산출된 feature map 각각 (그림에서는 depth방향으로 1024개) 평균내는 방식의 Pooling layer라고 생각하면 된다.
- 1차원 벡터로 만들어야 softmax를 사용할 수 있고, FC layer로 활성함수를 거치지 않아도 이미 깊은 네트워크를 거치면서 효과적으로 Feature vector를 추출했기 때문에, 이정도만해도 분류가 가능했다고 한다.
④ Auxiliary classification
- 네트워크가 하도 깊다보니 back propagation을 할 때 gradient 소실문제가 발생하기가 상대적으로 더 쉽다. 그래서 중간 정류장에서 gradient와 loss까지 계산해놓고, back propagation시에 도와준다고 한다.
- 훈련시에만 달아준다.
ResNet
마지막으로 2015년의 winner ResNet에 대해 알아보자

- 152 층으로 획기적으로 깊어졌다는 사실! ILSVRC'15와 COCO'15 분류 대회에서 모두 우승했다.
- ResNet 이름은 Residual network로, layer가 깊어질때 생기는 graidnet vanishing문제를 residual block이라는 방식을 통해 해결하고자 한 데에서 착안한 이름이다.
2. ResNet이 해결하고자 했던 것들
네트워크가 깊어지면 깊어질수록 풍부한 특징들을 추출할 수 있지만, 무작정 깊은 층을 쌓으면 성능이 저하되는 문제가 있었다.
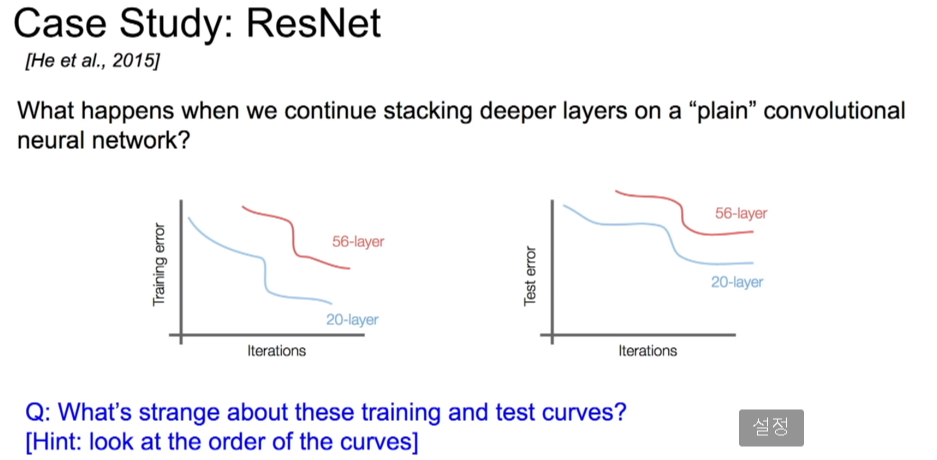
- 20층과 56층 CNN을 비교했을때, 56층이 train, test error모두 높았다.
- overfitting때문에 test error가 높은 것이라 생각할 수 있으나, train error도 높은 것으로 보아 overfitting의 문제만은 아니었다.
⇒ Optimization의 문제로 생각했다. deeper model은 Optimization이 더 어렵기 때문이다.
⇒ CNN을 깊게 쌓았을 때 성능이 저하되는 것이 Optimization의 문제라면, "얕은 네트워크의 구조를 그대로 가져와서, 추가로 쌓는 층은 input을 output으로 그대로 내보내는 identity mapping을 한다면, 적어도 얕은네트워크만큼의 성능은 나와야될 것이다" 라는 가정을 세웠다.
여기서 ResNet의 가장 큰 특징인 Residual learning이 등장한다.
3. Residual learning
- 단순히 깊은 CNN은 모델이 복잡해 최적화가 어려운 반면, 잔여학습(Residual learning)이라고 불리는 이 개념을 이용하면 네트워크의 최적화 난이도를 낮출 수 있었다 .
CNN 20층에 input과 output을 동일한 값으로 출력해주는 layer 36층을 더 쌓아 56층을 만들면 적어도 CNN 20층일때만큼의 성능은 나와야 하지 않을까?

왼쪽은 일반적인 CNN layer를 2층 쌓아서 $x_l$에서 $x_{l+2}$을 출력한 plain CNN network이다.
이 경우 층이 깊어질수록 계속해서 '곱셈'으로 연산이 이어지고, 때문에 backpropagation을 진행할 때 w 가중치의 기울기소실이 쉬워진다.
오른쪽 그림이 residual block의 개념인데, 2층의 layer를 더 쌓고 싶어서 쌓았을 때 초기 input인 $x_l$을 2번째 층의 relu 함수 (합성곱 다음이면서 비선형성을 더해주는 relu이전) 직전에 점프! 해서 보내버린다.
이를 short cut 또는 skip connection 이라고 하는데, 추가로 쌓아준 2층의 layer의 복잡하고 커다란 연산을 뛰어넘고 초기의 input정보를 더 깊은 layer로 지름길을 따라 보내준다는 의미이다.
이렇게 되면 $x_{l+2}$의 식은 $g(z_{l+2})$ 에서 $g(z_{l+2} + x_l)$로 변하게 된다.
이렇게 하면 처음에 적어도 20층에 동일한값을 출력해주는 추가 layer를 36층 더 깔아도 성능이 저하되지 않는 이유는 다음과 같다.
활성화함수로 ReLu함수를 사용했을 때 활성값은 무조건 양수이다.
이를 기반으로 방금 구한 최종 식을 다시 들여다보면,

$g(z_{l+2} + x_l)$ 을 풀어쓰면 $g(w_{l+2} x_{l+1} + x_l)$ 이된다.
여기서 네트워크의 층이 깊어질수록, 우리는 최적화의 일환으로 L2 regularization이나 weight decay 등의 기법을 사용할 것이고, 이에 따라 w값은 거의 0으로 소실될 것이다.
이에 따라 정말 깊은 네트워크에 가게 되면 w가 소실되어 $g(w_{l+2} x_{l+1} + x_l)$ 에서 $w_{l+2} x_{l+1}$가 0이 될 수도 있는데,
지름길로 보낸 $x_l$이 없었다면 이 노드는 그냥 사라져버렸을테지만, 덕분에 $g(x_l)$ 이 살아남았다.
그리고 이 $g(x_l)$ 이 relu를 거치면, $x_l$ 은 이전 layer에서 활성함수를 거친 활성값으로 항상 양수이기 때문에, 활성함수 relu인 g() 를 거치면 $x_l$ 이 나와서
최종 $x+2$ = $x_l$ 로 우리가 처음에 원했던, input과 output이 같은 추가 layer를 쌓을 수 있게된 것이다.
결과적으로 최소한 input값은 지켜주면서, 만약 추가로 쌓은 residual block 안의 layer들이 운좋게 학습도 하게 된다면, 성능이 최소한 상승하게 되는 것이다.
추가로 back propagation을 거칠때에도 매 residual block마다 $x_{l+2}$를 $x_l$에 대한 도함수를 구한다고 할 때 $g(w_{l+2} x_{l+1} + x_l)$ 과 같이 $+x_l$ 항 때문에 최소한 미분값이 1 이상을 유지하게 되어서 기울기소실문제도 발생하지 않는다.

강의의 그림을 다시보면, 일반적인 CNN layer를 거쳐온 거대한 합성곱으로 이루어진 H(x) 값을 학습하는 것보다
임의적으로 구성한 residual block 안에서 input X는 그대로 보내고, 그 안에서만 계산된 F(x)를 학습하는게 더 효율적이라는 생각에서 출발했고, 실제로 성능도 월등했다.
4. 전체 ResNet 구조

따라서 ResNet에서는 residual block으로 구성된 추가 layer를 깊게 쌓았다.
기본 구조는 VGG Net에서 가져왔고, 다음의 조건을 갖춘 Plain model을 만든 후 residual block을 적용한 model과 성능을 비교했다.
① 모든 residual block은 3x3 conv 2층을 가진다.
② 주기적으로 필터수를 2배씩 늘려주고, feature map 의 spatial dimension을 줄일 땐 pooling이 아닌 stride=2를 적용했다. 필터수를 늘린 이유는 feature map의 spatial dimension을 줄이면서 depth를 대신 늘려 layer 간 연산의 time complexity를 비슷하게 유지하려고 했다고 한다.
(그림에서 residual block 3개 건널때마다 필터수가 64 - 128 ...-512로 늘어남. 일종의 모델을 구성한 조건이고 이렇게 해보니 잘 돌아갔다더라~ 같다.)
③ VGGNet과는 다르게 마지막 FC layer들은 없애고 Global Average Pooling을 통해 softmax를 위한 1000개의 뉴런을 갖는 FC layer 하나만 갖는다. (parameter수를 확 줄여 연산량을 낮춤)

ResNet은 34층, 50층, 101층, 152층짜리가 있는데, 50층을 넘어가면 파라미터수가 급등하기 때문에 이를 효과적으로 조절하는 Bottle neck을 적용한다.
4. ResNet 추가 특징들

- 실제로는 매 Conv layer마다 배치놈을 사용했고, 가중치초기화는 Xavier/2 방법을 썼다.
- 경사하강법은 SGD + Momentum 방법을 썼고, 학습률은 0.1로 시작해서 뒤로갈수록 낮췄음
- 미니배치 256, weight decay
- dropout은 사용하지 않음
5. 결과

그 결과 2015년 이미지분류 대회들을 휩쓸었고
인간이 오차가 5%정도 나오는데, ResNet은 3.6%로 인간보다 정확했다.
모델별 비교 요약

2017년 기준으로 성능은 GoogleNet+Resnet을 합친 모델이 제일 좋았다고 한다.
- 오른쪽 표에서 원의 크기는 메모리크기, x축은 연산량, y축은 성능(정확도)이다.
1) VGG : 메모리가 굉장히 크고 연산량도 제일 많다.
2) GoogleNet : VGG와 비교해서 성능은 비슷한데도 불구하고 메모리와 연산량을 확 줄였다.
3) AlexNet : 연산량은 적지만 성능도 낮고 메모리도 크다.
4) ResNet : 메모리나 연산이 중간이고 성능이 제일 좋다.
출처
강의 : www.youtube.com/watch?v=DAOcjicFr1Y&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=9
'코딩 독학 > CS231n' 카테고리의 다른 글
| [cs231n] 11강. Detection and Segmentation (0) | 2020.12.19 |
|---|---|
| [cs231n] 10강. Recurrent Neural Networks (0) | 2020.12.12 |
| [cs231n] 7강. Training Neural Networks II (0) | 2020.11.21 |
| [cs231n] 6강. Training Neural Network 1 (0) | 2020.11.14 |
| [cs231n] 5강. Convolutional neural networks (0) | 2020.11.08 |




댓글